Desarrollo y validación de un
algoritmo de redes neuronales profundas para la predicción de parámetros
ambientales críticos en motores de inducción trifásicos: estudio experimental
en ambientes controlados
Development and validation of a
deep neural network algorithm for predicting critical environmental parameters
in three-phase induction motors: an experimental study under controlled
environments
Geovanna Shirley Agila Aguinda1 
 , Johnatan Israel Corrales Bonilla1
, Johnatan Israel Corrales Bonilla1

1Universidad Nacional de Chimborazo, Riobamba – Ecuador
Correo de correspondencia: geovanna.agila@unach.edu.ec; juanatan.corrales@unach.edu.ec
|
Información del artículo
Tipo de artículo:
Artículo original
Recibido:
20/02/2026
Aceptado:
25/03/2026
Publicado:
14/04/2026
Revista:
DATEH
|
Resumen
El monitoreo predictivo de motores de inducción trifásicos
constituye un desafío clave en entornos industriales debido a la complejidad
de las interacciones entre variables térmicas, eléctricas y mecánicas. En
este estudio se propone y valida un modelo de redes neuronales profundas tipo
LSTM multisalida para la predicción simultánea de la temperatura del estator,
la temperatura del rodamiento y la vibración RMS, utilizando datos
experimentales obtenidos en condiciones controladas. La metodología incluye
preprocesamiento, normalización sin fuga de información, construcción de
secuencias temporales mediante ventanas deslizantes y entrenamiento con
validación temporal. El desempeño fue evaluado mediante métricas MAE y RMSE,
junto con análisis de residuos, bootstrap y validación cruzada. Los
resultados muestran que el modelo LSTM alcanza un desempeño consistente, con
errores del orden de 6.8–7.0 °C en variables térmicas y aproximadamente 0.83
mm/s en vibración. La comparación con modelos tradicionales evidenció que
Random Forest presenta un mejor desempeño en variables térmicas, mientras que
el LSTM muestra ventajas en la modelación temporal y en la predicción de
vibración. Asimismo, se identificó una tendencia a generar predicciones
suavizadas, limitando la captura de fluctuaciones de alta frecuencia. La
prueba de hipótesis indicó que el modelo LSTM no presenta una mejora
estadísticamente significativa respecto a un modelo base. En conjunto, los
resultados evidencian que la selección del modelo depende de las características
del dataset, sugiriendo el uso de enfoques híbridos en aplicaciones
industriales.
Palabras clave: LSTM multisalida, motores
trifásicos, mantenimiento predictivo, series temporales multivariada, aprendizaje
profundo, análisis estadístico
Abstract
Predictive monitoring of three-phase induction motors is a
key challenge in industrial environments due to the complex interactions
between thermal, electrical, and mechanical variables. This study proposes
and validates a multivariate Long Short-Term Memory (LSTM) neural network
model for the simultaneous prediction of stator temperature, bearing
temperature, and RMS vibration using experimental data collected under
controlled conditions. The methodology includes preprocessing, leakage-free
normalization, temporal sequence construction using sliding windows, and
model training with temporal validation. Performance was evaluated using MAE
and RMSE metrics, complemented by residual analysis, bootstrap confidence
intervals, and time-series cross-validation. Results show that the LSTM model
achieves consistent performance, with errors of approximately 6.8–7.0 °C for
thermal variables and 0.83 mm/s for vibration. Comparison with traditional
models indicates that Random Forest outperforms LSTM in thermal prediction,
while LSTM provides advantages in temporal modeling and vibration prediction.
The model exhibits a smoothing effect, limiting its ability to capture
high-frequency fluctuations. Hypothesis testing revealed no statistically
significant improvement over a baseline model. Overall, the findings suggest
that model performance depends on dataset characteristics, highlighting the
potential of hybrid approaches for industrial applications.
Keywords: multi-output LSTM, three-phase
motors, predictive maintenance, time series, deep learning, statistical
analysis
|
INTRODUCCIÓN
En los últimos
años, el monitoreo inteligente de condición y la predicción del comportamiento
dinámico en sistemas electromecánicos se han vuelto cada vez más relevantes
para la industria moderna. Esto es particularmente cierto en sectores donde
mantener la continuidad operativa, optimizar la eficiencia energética y
garantizar la sostenibilidad de los procesos productivos son aspectos críticos.
Los motores de inducción trifásicos representan, sin duda, uno de los
componentes más empleados en entornos industriales; de hecho, son responsables
de una porción considerable del consumo energético a nivel mundial y resultan
fundamentales para el funcionamiento de sistemas de bombeo, compresión y
diversos mecanismos de accionamiento. Lei et al. (2020) y Zhu et al. (2023) han señalado que, dada la importancia de estos equipos, se
han venido desarrollando estrategias cada vez más sofisticadas de mantenimiento
predictivo que aprovechan el análisis de datos y las capacidades de la
inteligencia artificial.
Cuando
hablamos de "parámetros ambientales" en el contexto de sistemas
electromecánicos, no nos referimos únicamente a factores externos como la
temperatura del ambiente o los niveles de humedad. El concepto es más amplio e
incluye también las condiciones internas que caracterizan el entorno operativo
del sistema. Por ejemplo, variables como la temperatura del estator, la
temperatura en los rodamientos y los niveles de vibración se consideran
indicadores fundamentales del estado térmico y mecánico del motor, ya que
tienen un impacto directo en su eficiencia, rendimiento y, por supuesto, en
cuánto tiempo puede seguir funcionando de manera confiable.
Históricamente,
las estrategias de mantenimiento se han centrado en dos enfoques principales:
el correctivo, que actúa después de que ocurre una falla, y el preventivo, que
se basa en inspecciones programadas, análisis espectrales y límites
establecidos a partir de la experiencia práctica. El problema es que estos
métodos muestran sus debilidades cuando intentamos aplicarlos a sistemas
electromecánicos reales, que son inherentemente complejos. Estos sistemas
presentan comportamientos no lineales y múltiples interacciones entre variables
eléctricas, térmicas y mecánicas que están íntimamente relacionadas. Gangsar & Tiwari (2020) han
argumentado que los métodos que analizan señales de forma individual no
consiguen captar por completo cómo interactúan las distintas fuentes de
degradación. En la misma línea, Jiao et al. (2020) y Zhang et al. (2020) han
documentado que estos enfoques tradicionales tienen problemas para adaptarse
cuando hay ruido en las señales o cuando las condiciones operativas varían.
Ante estas
limitaciones, el mantenimiento predictivo basado en datos ha ganado terreno de
manera notable durante la última década. Según lo planteado por Theissler et al. (2021) y Xu & Saleh (2021), las
técnicas de machine learning ofrecen la posibilidad de convertir enormes
cantidades de datos históricos en información realmente útil para detectar
fallas antes de que ocurran y para anticipar el comportamiento del sistema. Los
modelos de aprendizaje profundo, en particular, han demostrado ser bastante
efectivos cuando se trata de representar sistemas dinámicos complejos. Tama et al. (2023) y Qiu et al. (2023) han
encontrado que estas arquitecturas profundas logran mejores resultados que los
métodos convencionales en tareas de diagnóstico y pronóstico aplicadas a
maquinaria rotativa.
Entre las
diferentes técnicas disponibles, las redes Long Short-Term Memory (LSTM) se han
popularizado bastante para analizar series temporales en contextos
industriales. La razón principal es que tienen la capacidad de identificar
patrones tanto a corto como a largo plazo, lo cual resulta crucial cuando
estamos estudiando fenómenos de degradación que avanzan de forma gradual. Deng et al. (2021) y Wang et al. (2024) han
reportado que el uso de modelos LSTM produce mejoras notables en métricas de
error como MAE y RMSE al predecir variables térmicas. Por su parte, Kirchgässner et al. (2021) y
Hughes et al. (2023)
enfatizan que incluir variables que tengan sentido desde el punto de vista
físico ayuda a mejorar considerablemente la precisión de estos modelos.
A pesar de
todo esto, todavía quedan retos por resolver. Varios estudios han observado que
los modelos de aprendizaje profundo a veces tienen dificultades para captar
fluctuaciones rápidas o cambios transitorios, sobre todo cuando los datos
vienen de experimentos controlados donde la variabilidad es más bien limitada.
En esos casos, los modelos suelen representar bien la tendencia general del
sistema, pero les cuesta más trabajo reproducir eventos súbitos o cambios
bruscos.
En cuanto al
diagnóstico de fallas, se han llevado a cabo numerosas investigaciones que usan
aprendizaje automático para identificar patrones anormales en señales de
vibración, corriente eléctrica y temperatura. Zhao et al. (2020) y Neupane & Seok (2020), por
ejemplo, han mostrado mejoras importantes en la detección de fallas en
rodamientos utilizando modelos de deep learning. Singh et al. (2023) y H. Wang et al. (2023) también
han destacado lo útil que puede ser la inteligencia artificial para detectar
anomalías de forma temprana en maquinaria rotativa.
Sin embargo,
hay algo que llama la atención al revisar la literatura: muchos estudios tratan
las variables físicas de manera separada. Cen et al. (2022) y Nikfar et al, (2022) han
notado que es común que las investigaciones aborden las variables térmicas,
eléctricas y mecánicas de forma aislada, lo que termina limitando la capacidad
de entender cómo realmente interactúan entre sí dentro del sistema. Esto es
especialmente problemático en motores eléctricos, donde sabemos que estos
fenómenos están fuertemente conectados.
Un aspecto que
resulta especialmente crítico es la forma en que se estructura el pipeline de
análisis de datos. Tal como señala Lei et al. (2020), una
configuración inadecuada del proceso de entrenamiento puede conducir a modelos
con sobreajuste o a estimaciones de desempeño que no reflejan su comportamiento
real. En este sentido, la literatura reciente enfatiza la necesidad de aplicar
esquemas de validación temporal estrictos y de preservar conjuntos de prueba
completamente independientes, con el fin de obtener evaluaciones más
confiables.
En este
trabajo se plantea el desarrollo de un modelo LSTM multisalida orientado a la
predicción simultánea de la temperatura del estator, la temperatura del
rodamiento y la vibración mecánica en motores de inducción trifásicos. A
diferencia de enfoques convencionales, la propuesta integra múltiples variables
físicas dentro de una misma arquitectura, lo que permite aproximarse de forma
más completa a la dinámica real del sistema.
Además, no
solo se busca estimar estas variables, sino también analizar en qué medida el
modelo es capaz de seguir su evolución temporal. En particular, se presta
atención a sus limitaciones, sobre todo en escenarios donde se presentan
cambios rápidos o transitorios. Para ello, se implementa una metodología
estructurada que incluye el preprocesamiento de datos, la construcción de
secuencias mediante ventanas deslizantes y la validación bajo un enfoque
temporal.
Más allá de
los indicadores cuantitativos, el interés también se centra en comprender cómo
responde el modelo en condiciones controladas, identificando tanto sus
fortalezas como sus restricciones. Este tipo de análisis resulta relevante para
el desarrollo de aplicaciones basadas en inteligencia artificial orientadas al
monitoreo de sistemas electromecánicos, donde la interpretación del
comportamiento del modelo es tan importante como su precisión numérica.
MATERIALES Y MÉTODOS
Diseño
de la investigación
La
investigación se desarrolló bajo un enfoque cuantitativo, con alcance aplicado
y experimental, orientado al desarrollo y validación de un algoritmo de redes
neuronales profundas para la predicción de parámetros ambientales críticos en
motores de inducción trifásicos. El estudio se basa en el análisis de datos
experimentales obtenidos en ambientes controlados, lo que permitió evaluar el
comportamiento del sistema electromecánico bajo condiciones reproducibles de
laboratorio.
El
diseño metodológico corresponde a un estudio longitudinal de series temporales
multivariables, dado que las variables fueron registradas de forma secuencial
en el tiempo. Este enfoque es coherente con el objetivo de anticipar
comportamientos críticos asociados al desempeño térmico y vibracional del
motor.
Materiales
e instrumentación
El
estudio se realizó sobre un único sistema experimental, basado en motores de
inducción trifásicos de jaula de ardilla con características técnicas
equivalentes, instrumentados con sensores industriales para la medición de
variables ambientales, eléctricas, térmicas y mecánicas. Los motores fueron
operados de manera alternada dentro del mismo entorno experimental y bajo
condiciones controladas de laboratorio. Con el fin de evitar sesgos asociados a
la identificación individual de cada equipo, los registros temporales fueron
analizados de forma agregada, sin asignar etiquetas específicas por motor. La
Tabla 1, presenta el resumen de los materiales e instrumentos utilizados en el
sistema experimental.
Tabla 1
Materiales e instrumentos empleados en el sistema
experimental.
|
Elemento
|
Descripción General
|
Medidas / Unidades
|
|
Motor de inducción
|
Motor trifásico de jaula de ardilla
|
Potencia nominal ≈ 5 kW
|
|
Sensor de temperatura
|
Sensor industrial de contacto / ambiente
|
°C
|
|
Sensor de humedad
|
Sensor ambiental
|
%
|
|
Sensor de flujo de aire
|
Anemómetro industrial
|
m/s
|
|
Sensor de vibración
|
Sensor de vibración industrial
|
mm/s
|
|
Sensores eléctricos
|
Sensores de corriente y voltaje
|
A, V
|
|
Sistema de adquisición
|
Sistema multicanal sincronizado
|
Registro temporal
|
|
Sistema computacional
|
Computador de propósito general
|
Procesamiento de datos
|
Configuración
del sistema experimental
El
sistema experimental fue configurado de manera que los sensores ambientales,
eléctricos, térmicos y mecánicos operaran de forma sincronizada durante el
funcionamiento del motor. La disposición de los sensores permitió capturar
información representativa de las condiciones de operación del sistema,
asegurando coherencia temporal entre las variables medidas.
La
adquisición de datos se realizó mediante un sistema multicanal sincronizado, lo
que permitió registrar de forma simultánea todas las magnitudes físicas
consideradas en el estudio.
Procedencia
y recolección de los datos
El
conjunto de datos utilizado en esta investigación corresponde a registros
experimentales obtenidos a partir de un sistema electromecánico instrumentado,
operado bajo condiciones controladas en un entorno de laboratorio.
Posteriormente, dichos datos fueron proporcionados para su análisis,
procesamiento y modelado, constituyendo la base experimental del presente
estudio.
El
proceso de recolección no involucró participantes humanos ni seres vivos, por
lo que no se requirieron consentimientos informados ni consideraciones éticas
adicionales.
Descripción
del dataset
El
dataset empleado en el análisis está conformado por 1500 registros
experimentales, organizados como una serie temporal multivariable, sin
identificación por unidad individual. Esta característica indica que los datos
corresponden a una única configuración experimental, basada en un motor
instrumentado, y que el análisis se realiza sobre el comportamiento agregado
del sistema.
Para
facilitar la comprensión de la estructura general del conjunto de datos, la
Tabla 2 resume sus principales características.
Tabla 2
Estructura general del dataset.
|
Característica
|
Descripción
|
|
Tipo de datos
|
Serie temporal multivariable
|
|
Número de registros
|
1500
|
|
Sistema analizado
|
Sistema experimental con motores equivalentes operados de forma
alternada
|
|
Entorno
|
Ambiente controlado
|
|
Identificación por unidad
|
No disponible
|
|
Finalidad
|
Predicción de parámetros críticos
|
Variables
consideradas
Las
variables incluidas en el dataset fueron clasificadas según su naturaleza
física y su rol dentro del modelo predictivo. Esta clasificación permitió
definir de manera clara las variables de entrada y las variables objetivo del
algoritmo de redes neuronales profundas.
La
Tabla 3 presenta el detalle de las variables consideradas, junto con sus
unidades de medida y su función dentro del modelo.
Tabla 3
Variables del dataset.
|
Variable
|
Tipo
|
Unidad
|
Rol
|
|
Temperatura ambiente
|
Ambiental
|
°C
|
Entrada
|
|
Humedad relativa
|
Ambiental
|
%
|
Entrada
|
|
Velocidad del aire
|
Ambiental
|
m/s
|
Entrada
|
|
Carga del motor
|
Operativa
|
%
|
Entrada
|
|
Tensión de línea
|
Eléctrica
|
V
|
Entrada
|
|
Corriente de línea
|
Eléctrica
|
A
|
Entrada
|
|
Potencia activa
|
Eléctrica
|
kW
|
Entrada
|
|
Velocidad de rotación
|
Mecánica
|
rpm
|
Entrada
|
|
Vibración global
|
Mecánica
|
mm/s
|
Salida
|
|
Temperatura del estator
|
Térmica
|
°C
|
Salida
|
|
Temperatura del rodamiento
|
Térmica
|
°C
|
Salida
|
|
Severidad ambiental
|
Derivada
|
—
|
Entrada
|
Preprocesamiento
y análisis de datos
Previo
al proceso de modelado, el dataset fue sometido a un análisis exploratorio de
datos, con el fin de identificar rangos operativos, tendencias generales y
posibles valores atípicos. Posteriormente, se aplicaron técnicas de
preprocesamiento, que incluyeron la depuración de datos inconsistentes y la
normalización de las variables de entrada, garantizando estabilidad numérica
durante el entrenamiento del modelo.
Los
datos fueron reorganizados en secuencias temporales mediante el uso de ventanas
deslizantes, lo que permitió capturar dependencias temporales relevantes para
el enfoque de redes neuronales profundas.
Pipeline
metodológico del algoritmo propuestos
Con
el objetivo de garantizar la reproducibilidad del estudio, se definió un
pipeline metodológico estructurado, que integra de manera secuencial todas las
etapas seguidas desde la disponibilidad del dataset hasta la obtención de los
resultados predictivos.
Para
efectos de claridad conceptual, el pipeline se organiza en tres macro-etapas
principales:
(i)
gestión y preparación de datos,
(ii)
modelado mediante redes neuronales profundas, y
(iii)
evaluación e interpretación de resultados.
La
Tabla 4 presenta el detalle de los procesos que componen cada una de estas
macro-etapas, mientras que la Figura 1 muestra una representación esquemática y
sintetizada del flujo metodológico adoptado en el estudio.
Tabla 4
Pipeline metodológico del estudio
|
Etapa
|
Proceso
|
Descripción
|
|
1
|
Gestión del dataset
|
Verificación de estructura y coherencia temporal
|
|
2
|
Análisis exploratorio
|
Estadística descriptiva y detección de atípicos
|
|
3
|
Preprocesamiento
|
Depuración y normalización de datos
|
|
4
|
Secuenciación temporal
|
Construcción de ventanas deslizantes
|
|
5
|
Definición del modelo
|
Selección de variables de entrada y salida
|
|
6
|
Modelado
|
Diseño del algoritmo de red neuronal profunda
|
|
7
|
Entrenamiento
|
Ajuste de parámetros del modelo
|
|
8
|
Validación
|
Evaluación mediante métricas estadísticas
|
|
9
|
Comparación
|
Análisis frente a métodos alternativos
|
|
10
|
Interpretación
|
Análisis de resultados predictivos
|
La
Figura 1, muestra una representación esquemática y sintetizada del pipeline
metodológico, organizado en tres macro-etapas: gestión de datos, modelado con
redes neuronales profundas y evaluación de resultados.
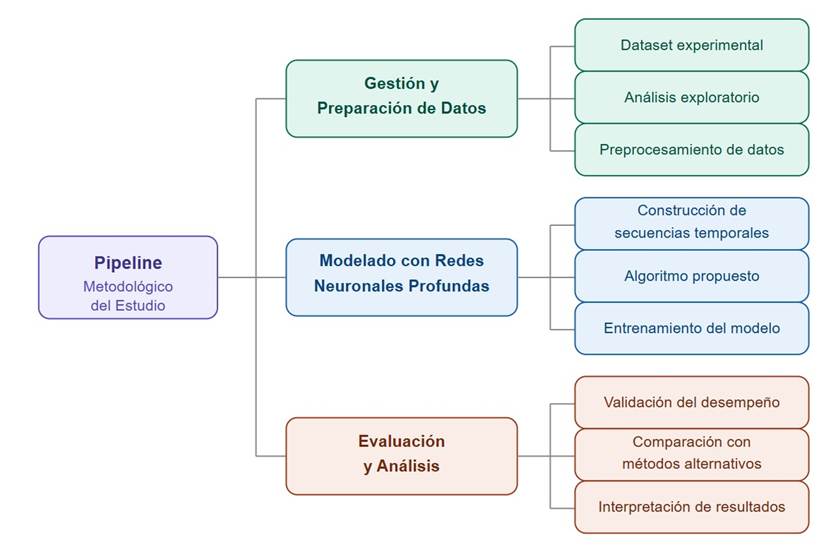
Figura 1. Pipeline esquemático del
proceso metodológico
Consideraciones
éticas
La
investigación no involucró participantes humanos ni seres vivos. El estudio se
realizó exclusivamente sobre un sistema electromecánico instrumentado,
cumpliendo las normas de seguridad del laboratorio y los principios de uso
responsable de los datos experimentales.
RESULTADOS
Los
resultados se presentan mediante un enfoque integral que combina análisis
exploratorio, evaluación cuantitativa, validación del modelo y discusión
crítica en relación con la literatura especializada. A diferencia de enfoques
puramente descriptivos, esta sección incorpora análisis estadístico, evaluación
de generalización y verificación explícita de posibles fenómenos de
sobreajuste, con el fin de garantizar la validez científica de los resultados.
1.
Validación y análisis del dataset
1.1. Validación estructural del dataset
El
conjunto de datos empleado en este estudio corresponde a una serie temporal
multivariada compuesta por 1500 registros, obtenidos con un intervalo de
muestreo constante de cinco minutos. Este dataset integra variables de distinta
naturaleza —ambientales, eléctricas, mecánicas y térmicas— que, en conjunto,
permiten describir el comportamiento operativo de un sistema electromecánico
basado en motores de inducción.
Desde
el punto de vista estructural, el conjunto de datos incluye 13 variables: una
variable temporal (timestamp), once variables numéricas y una variable
categórica (environmental_severity). Al revisar la integridad de los datos, no
se identificaron valores nulos, inconsistencias ni registros atípicos que
requirieran procesos adicionales de limpieza. Esto facilita el análisis
posterior y aporta confianza en la calidad de la información utilizada para el
entrenamiento del modelo.
Un
aspecto que vale la pena mencionar es el comportamiento de la variable
categórica environmental_severity, la cual mantiene un único valor (“Normal”) a
lo largo de toda la serie temporal. Esto sugiere que los datos fueron
recolectados bajo condiciones operativas estables y controladas. Si bien esta
característica contribuye a la coherencia del dataset, también introduce una
limitación: la ausencia de variabilidad en el entorno puede afectar la
capacidad del modelo para generalizar en escenarios más diversos o con
condiciones menos controladas.
1.2. Análisis estadístico descriptivo
Con
el objetivo de caracterizar el comportamiento de las variables del sistema, se
realizó un análisis estadístico descriptivo considerando medidas de tendencia
central, dispersión y rango. Los resultados obtenidos se presentan en la Tabla
5.
Tabla 5
Estadística descriptiva de las variables numéricas del
dataset experimental.
|
Variable
|
Media
|
Desv. Est.
|
Mín
|
P25
|
Mediana
|
P75
|
Máx
|
|
Temperatura ambiente (°C)
|
28,16
|
2,92
|
22,00
|
26,13
|
28,15
|
30,04
|
38,00
|
|
Humedad relativa (%)
|
78,08
|
5,87
|
59,88
|
74,19
|
77,99
|
82,02
|
95,00
|
|
Flujo de aire (m/s)
|
2,47
|
0,61
|
1,00
|
2,06
|
2,49
|
2,87
|
4,45
|
|
Carga del motor (%)
|
69,85
|
17,38
|
40,01
|
54,61
|
69,49
|
85,54
|
99,97
|
|
Voltaje de línea (V)
|
399,64
|
8,27
|
374,23
|
393,91
|
399,58
|
405,44
|
428,23
|
|
Corriente de línea (A)
|
10,51
|
3,04
|
2,00
|
8,16
|
10,48
|
12,90
|
19,84
|
|
Potencia activa (kW)
|
6,18
|
1,79
|
1,15
|
4,79
|
6,18
|
7,57
|
11,57
|
|
Velocidad de rotación (rpm)
|
1479,81
|
14,36
|
1421,16
|
1470,19
|
1480,00
|
1489,45
|
1527,37
|
|
Vibración (mm/s)
|
2,49
|
0,78
|
0,50
|
1,97
|
2,47
|
3,01
|
5,20
|
|
Temperatura del estator (°C)
|
55,17
|
7,06
|
37,21
|
49,75
|
55,13
|
60,82
|
73,68
|
|
Temperatura del rodamiento (°C)
|
51,14
|
7,11
|
31,08
|
45,69
|
51,04
|
56,58
|
69,81
|
Como
se observa en la Tabla 5, las variables eléctricas presentan un comportamiento
altamente estable, con valores de voltaje cercanos a 400 V y una variabilidad
moderada en corriente y potencia activa. Este comportamiento es consistente con
la operación de un sistema industrial bajo condiciones nominales. La velocidad
de rotación del motor se mantiene alrededor de 1480 rpm, lo cual concuerda con
el régimen esperado de un motor de inducción trifásico en condiciones de carga
constante. Por su parte, las variables térmicas (temperatura del estator y del
rodamiento) presentan una dispersión moderada, reflejando la respuesta térmica
del sistema ante variaciones en la carga. En relación con la vibración, los
valores registrados muestran una baja dispersión relativa, lo que sugiere la
ausencia de eventos anómalos o fallas mecánicas significativas durante el
periodo de estudio. Este comportamiento indica que el dataset representa
predominantemente condiciones de operación normal, lo cual debe considerarse en
la interpretación de los resultados del modelo.
1.3. Relación entre variables y preprocesamiento
Para
analizar las relaciones entre las variables del sistema, se calculó la matriz
de correlación de Pearson, cuyos resultados se presentan en la Figura 2.
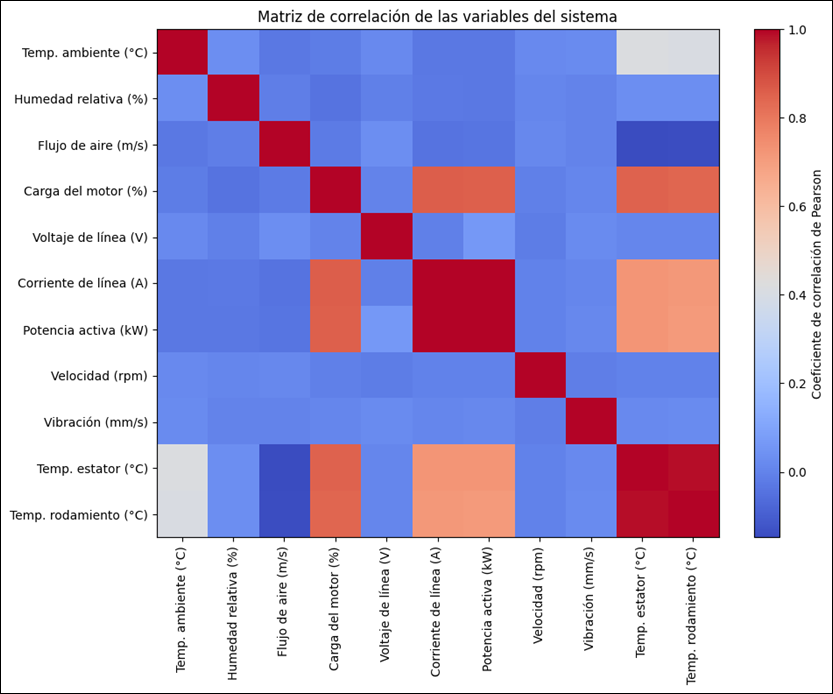
Figura 2. Matriz de correlación de
las variables numéricas del dataset experimental.
El
análisis de la Figura 2 revela la existencia de relaciones altamente
significativas entre variables eléctricas y operativas. En particular, se
observa una fuerte correlación entre la corriente de línea y la potencia
activa, así como entre la carga del motor y dichas variables, lo cual es
consistente con los principios físicos que gobiernan el comportamiento de
sistemas electromecánicos.
Asimismo,
se identifica una alta correlación entre la temperatura del estator y la
temperatura del rodamiento, lo que evidencia el acoplamiento térmico entre los
componentes del sistema. Este comportamiento es esperable debido a la
transferencia de calor generada durante la operación del motor.
En
contraste, la variable de vibración presenta correlaciones bajas con la mayoría
de las variables analizadas, lo que sugiere una dinámica parcialmente
independiente. Este hallazgo resulta particularmente relevante, ya que permite
explicar el comportamiento del modelo predictivo en etapas posteriores.
Específicamente, la baja correlación de la vibración con otras variables limita
la capacidad del modelo para capturar sus variaciones a partir de dependencias
multivariadas, favoreciendo una tendencia a la suavización en las predicciones.
2.
Construcción y entrenamiento del modelo
2.1
Preparación de los datos para el modelado
Los
datos fueron ordenados temporalmente según la variable timestamp para preservar
la coherencia secuencial. Se definieron ocho variables de entrada (features) y
tres variables objetivo (targets): temperatura del estator, temperatura del
rodamiento y vibración RMS, conforme a la Tabla 3. El dataset fue dividido
mediante un esquema temporal en entrenamiento (70%), validación (15%) y prueba
(15%), evitando fuga de información. Posteriormente, se aplicó un escalado
Min-Max ajustado únicamente con el conjunto de entrenamiento y luego aplicado a
los demás subconjuntos. Finalmente, los datos fueron reorganizados en
secuencias mediante ventanas deslizantes con un tamaño de 12 pasos (60 min) y
un horizonte de 1 paso (5 min), permitiendo capturar dependencias temporales
relevantes.
2.2
Configuración de la arquitectura LSTM multisalida
Para
modelar la dinámica temporal multivariada del sistema, se implementó una red
neuronal recurrente tipo LSTM multisalida orientada a regresión. La
arquitectura estuvo compuesta por dos capas LSTM consecutivas de 64 y 32
unidades, respectivamente, complementadas con capas de regularización Dropout
con una tasa de 0,10, con el fin de mejorar la capacidad de generalización del
modelo y reducir el riesgo de sobreajuste. Posteriormente, se incorporó una
capa densa intermedia de 32 neuronas con función de activación ReLU, seguida de
una capa de salida lineal de tres neuronas, correspondiente a la predicción
simultánea de la temperatura del estator, la temperatura del rodamiento y la
vibración RMS. El modelo fue entrenado utilizando el optimizador Adam con una
tasa de aprendizaje de 0,001, empleando como función de pérdida la función Huber
y como métrica de evaluación el error absoluto medio (MAE). La configuración
final del modelo y sus principales hiperparámetros se resumen en la Tabla 6.
Tabla 6
Hiperparámetros y configuración del modelo de redes neuronales
profundas
|
Parámetro
|
Valor
|
|
Tipo de modelo
|
LSTM multisalida (regresión)
|
|
Tamaño de ventana (lookback)
|
12 pasos (≈ 60 min)
|
|
Horizonte de predicción
|
1 paso (≈ 5 min)
|
|
Entradas (features)
|
8 variables
|
|
Salidas (targets)
|
3 variables
|
|
Capa LSTM 1
|
64 unidades, return_sequences=True
|
|
Capa LSTM 2
|
32 unidades, return_sequences=False
|
|
Regularización
|
Dropout = 0,10
|
|
Capa densa intermedia
|
Dense(32), activación ReLU
|
|
Capa de salida
|
Dense(3), activación lineal
|
|
Función de pérdida
|
Huber (δ = 1.0)
|
|
Optimizador
|
Adam
|
|
Learning rate
|
0,001
|
|
Métrica reportada
|
MAE
|
|
Parámetros entrenables totales
|
32 259
|
La implementación se realizó en TensorFlow 2.19.0.
2.3
Entrenamiento y validación del modelo
El
modelo fue entrenado durante un máximo de 100 épocas, con un tamaño de lote de
32 muestras, utilizando Early Stopping con una paciencia de 10 épocas y
monitoreo del error de validación. El proceso de entrenamiento finalizó en la
época 15, alcanzando su mejor desempeño en la época 6. En este punto, el modelo
obtuvo un MSE de 0.0391 en entrenamiento y 0.0396 en validación, así como
valores de MAE de 0.1634 y 0.1625, respectivamente, como se muestra en la Tabla
7.
Tabla 7
Resultados finales del entrenamiento del
modelo LSTM
|
Métrica
|
Valor
|
|
Épocas totales
|
15
|
|
Mejor época
|
6
|
|
MSE entrenamiento
|
0.0391
|
|
MSE validación
|
0.0396
|
|
MAE entrenamiento
|
0.1634
|
|
MAE validación
|
0.1625
|
La
evolución del proceso de entrenamiento puede observarse en las curvas de error presentadas
en la Figura 3 (MSE) y la Figura 4 (MAE), donde se evidencia una convergencia
estable y sin divergencias significativas entre entrenamiento y validación.
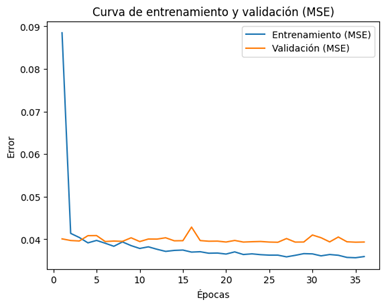
Figura 3. Curva
de entrenamiento y validación del error cuadrático medio (MSE).
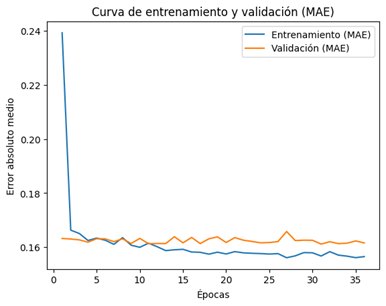
Figura 4. Curva de
entrenamiento y validación del error absoluto medio (MAE).
La
similitud entre las métricas de entrenamiento y validación indica una adecuada
capacidad de generalización y ausencia de sobreajuste clásico. No obstante, el
modelo presenta una mayor capacidad para capturar la tendencia global del
sistema que las fluctuaciones de alta frecuencia, aspecto que será analizado en
las secciones posteriores.
3. Validación del modelo en el
conjunto de prueba
3.1 Evaluación del desempeño en el conjunto
de prueba
El desempeño del modelo fue evaluado
utilizando el conjunto de prueba, considerando como métricas el error absoluto
medio (MAE) y la raíz del error cuadrático medio (RMSE). Los resultados
obtenidos se presentan en la Tabla 8.
Tabla 8
Métricas de desempeño del modelo en el conjunto de prueba.
|
Variable objetivo
|
MAE
|
RMSE
|
|
Temperatura del estator (°C)
|
5.6924
|
6.8681
|
|
Temperatura del rodamiento (°C)
|
5.7924
|
7.0254
|
|
Vibración RMS (mm/s)
|
0.6626
|
0.8275
|
Los
valores obtenidos evidencian un comportamiento consistente del modelo en las
tres variables objetivo. En particular, se obtuvo un MAE de 5.6924 °C y un RMSE
de 6.8681 °C para la temperatura del estator, así como un MAE de 5.7924 °C y un
RMSE de 7.0254 °C para la temperatura del rodamiento. En el caso de la
vibración RMS, el modelo alcanzó un MAE de 0.6626 mm/s y un RMSE de 0.8275
mm/s, reflejando una adecuada capacidad predictiva en términos generales.
3.2 Comparación entre valores reales
y predichos
Para analizar el comportamiento temporal
del modelo, se compararon los valores reales y predichos en el conjunto de
prueba. Los resultados se muestran en las Figuras 5, 6 y 7. En la Figura 5,
correspondiente a la temperatura del estator, se observa que el modelo
reproduce adecuadamente la tendencia global de la señal, aunque presenta una
ligera suavización en los cambios abruptos.
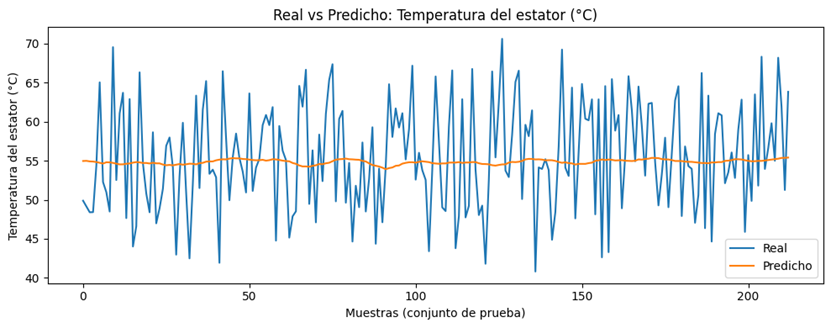
Figura 5. Valores
reales vs predichos de la Temperatura del estator.
En
la Figura 6, asociada a la temperatura del rodamiento, se identifica un
comportamiento similar, donde el modelo mantiene una buena aproximación
general, pero con desviaciones en los picos locales.
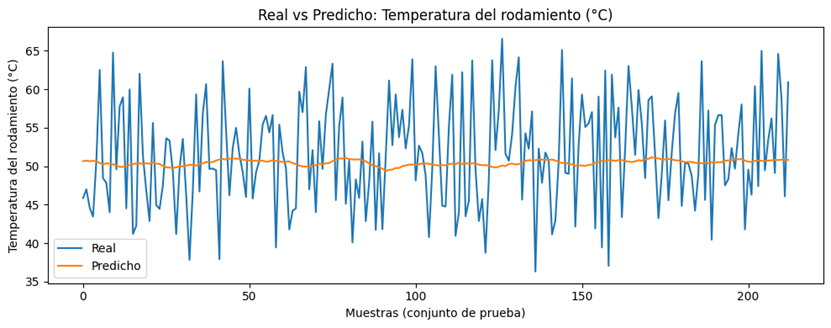
Figura 6. Valores
reales vs predichos de la Temperatura del rodamiento.
Por su parte, la
Figura 7, correspondiente a la vibración RMS, muestra una mayor dispersión
entre valores reales y predichos. Este comportamiento se relaciona con la menor
correlación de esta variable respecto a las demás, dificultando su modelado
preciso.
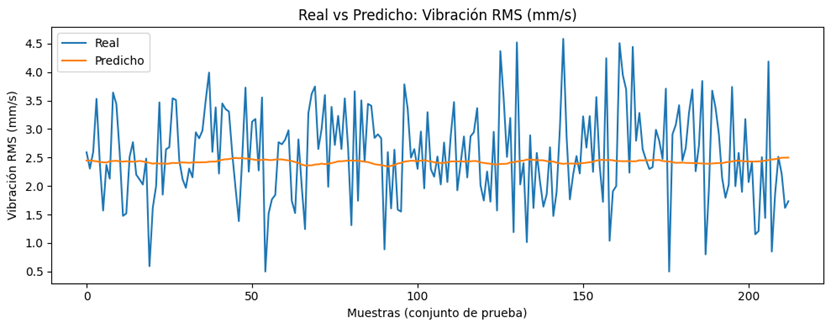
Figura 7. Valores
reales vs predichos de la Vibración RMS del motor.
En conjunto,
los resultados evidencian que el modelo captura adecuadamente la dinámica
global del sistema, aunque presenta limitaciones en la representación de
fluctuaciones de alta frecuencia.
Este
comportamiento confirma la ausencia de sobreajuste clásico, pero evidencia un
fenómeno de suavización asociado a la priorización de la tendencia global sobre
fluctuaciones de alta frecuencia.
4. Análisis estadístico del error
4.1
Análisis de residuos
Con
el objetivo de evaluar la calidad de las predicciones, se analizó la distribución
de los residuos definidos como la diferencia entre los valores reales y los
valores predichos. Los resultados se presentan en la Tabla 9.
Tabla 9
Estadísticos descriptivos de los residuos en el conjunto de prueba
|
Variable
|
Media
|
Desv. estándar
|
Mediana
|
P25
|
P75
|
Mín
|
Máx
|
|
Estator (°C)
|
0.7466
|
6.8435
|
0.0752
|
-4.8804
|
6.2513
|
-14.3530
|
16.0838
|
|
Rodamiento (°C)
|
1.1574
|
6.9457
|
0.8678
|
-4.7102
|
6.3183
|
-14.4649
|
16.4715
|
|
Vibración (mm/s)
|
0.1342
|
0.8184
|
0.1185
|
-0.4061
|
0.7431
|
-1.9659
|
2.1933
|
Los
valores medios de los residuos son relativamente cercanos a cero, lo que indica
una ausencia de sesgo sistemático significativo en el modelo. Sin embargo, se
observa una ligera tendencia positiva en las variables térmicas, especialmente
en la temperatura del rodamiento, lo que sugiere una leve subestimación de los
valores reales. La desviación estándar de los residuos es mayor en las
variables térmicas (≈ 6.8–6.9 °C) en comparación con la vibración (≈ 0.82
mm/s), reflejando una mayor variabilidad del error en las variables asociadas a
procesos térmicos.
4.2
Pruebas de normalidad de los residuos
Para
evaluar la distribución de los residuos, se aplicaron las pruebas de
Shapiro–Wilk y Kolmogorov–Smirnov, cuyos resultados se resumen en la Tabla 10.
Estas pruebas permiten verificar si los errores se aproximan a una distribución
normal, condición relevante para el análisis estadístico del desempeño del
modelo.
Tabla 10
Resultados de las pruebas de normalidad de los residuos
|
Variable
|
Shapiro–Wilk p-value
|
Kolmogorov–Smirnov p-value
|
|
Estator (°C)
|
0.0097
|
0.5339
|
|
Rodamiento (°C)
|
0.0214
|
0.5358
|
|
Vibración (mm/s)
|
0.6691
|
0.9301
|
Los
resultados de la prueba de Shapiro-Wilk indican que las variables térmicas no
siguen una distribución normal (p < 0.05), mientras que la variable de
vibración sí presenta comportamiento aproximadamente normal (p > 0.05). Por
otro lado, la prueba de Kolmogorov-Smirnov no evidencia desviaciones
significativas respecto a la normalidad en ninguna de las variables, lo cual
sugiere que la distribución de los residuos, aunque no estrictamente normal, es
estadísticamente aceptable para fines de modelado.
4.3
Intervalos de confianza de las métricas de error
Con
el objetivo de cuantificar la incertidumbre asociada a las métricas de
desempeño, se estimaron intervalos de confianza al 95 % para el MAE y el RMSE
mediante remuestreo bootstrap. La Tabla 11 presenta los valores medios y sus
respectivos intervalos.
Tabla 11
Intervalos de confianza (95 %) de las métricas de error en el
conjunto de prueba
|
Variable
|
MAE
|
IC95% MAE
|
RMSE
|
IC95% RMSE
|
|
Estator (°C)
|
5.6880
|
[5.1552–6.2248]
|
6.8568
|
[6.3416–7.4004]
|
|
Rodamiento (°C)
|
5.7933
|
[5.2679–6.3036]
|
7.0203
|
[6.4691–7.5288]
|
|
Vibración (mm/s)
|
0.6626
|
[0.5987–0.7312]
|
0.8274
|
[0.7527–0.9040]
|
Los
intervalos obtenidos muestran una baja variabilidad en las métricas, lo que
indica estabilidad en el desempeño del modelo. En particular, los rangos de
RMSE para las variables térmicas se mantienen dentro de intervalos estrechos,
evidenciando consistencia en las predicciones.
4.4
Validación temporal cruzada
Con
el fin de evaluar la estabilidad del modelo bajo diferentes segmentos
temporales, se aplicó un esquema de validación cruzada basado en
TimeSeriesSplit. Este enfoque permite preservar la dependencia temporal de los
datos y evitar fuga de información. Los resultados muestran valores de RMSE
comprendidos entre 5.00 °C y 5.10 °C, con MAE entre 4.17 °C y 4.28 °C,
evidenciando una consistencia del desempeño del modelo en distintos
subconjuntos temporales. Estos resultados son coherentes con la evaluación sobre
el conjunto de prueba independiente, lo que refuerza la capacidad de
generalización del modelo.
Tabla 12
Validación temporal (TimeSeriesSplit)
|
Fold
|
MAE
|
RMSE
|
Train
|
Test
|
|
1
|
4.2861
|
5.0985
|
372
|
372
|
|
2
|
4.2086
|
5.0032
|
744
|
372
|
|
3
|
4.1744
|
5.0557
|
1116
|
372
|
5.
Comparación con métodos alternativos
5.1
Comparación cuantitativa con modelos tradicionales
Con
el objetivo de evaluar el desempeño del modelo propuesto, se realizó una
comparación con modelos tradicionales de regresión, específicamente Random
Forest y XGBoost. Los resultados obtenidos se presentan en la Tabla 13.
Tabla 13
Comparación del desempeño del modelo LSTM multisalida con métodos
alternativos (ARIMA robusto, Random Forest y XGBoost)
|
Modelo
|
Variable
|
RMSE
|
MAE
|
|
Random Forest
|
Estator (°C)
|
6.7736
|
5.6502
|
|
Random Forest
|
Rodamiento (°C)
|
6.9017
|
5.7303
|
|
Random Forest
|
Vibración (mm/s)
|
0.8316
|
0.6587
|
|
XGBoost
|
Estator (°C)
|
6.9771
|
5.8021
|
|
XGBoost
|
Rodamiento (°C)
|
7.0274
|
5.7610
|
|
XGBoost
|
Vibración (mm/s)
|
0.8815
|
0.6920
|
|
LSTM
|
Estator (°C)
|
6.8681
|
5.6924
|
|
LSTM
|
Rodamiento (°C)
|
7.0254
|
5.7924
|
|
LSTM
|
Vibración (mm/s)
|
0.8275
|
0.6626
|
(Métricas RMSE y MAE calculadas sobre el conjunto de prueba;
valores en unidades reales de cada variable)
El
modelo Random Forest mostró el mejor desempeño en las variables térmicas,
alcanzando un RMSE de 6.7736 °C para la temperatura del estator y 6.9017 °C
para la temperatura del rodamiento, superando ligeramente al modelo LSTM. Por
su parte, el modelo XGBoost presentó un desempeño inferior en comparación con
los otros enfoques evaluados.
El
modelo LSTM multisalida obtuvo resultados competitivos, con valores de RMSE de
6.8681 °C para el estator y 7.0254 °C para el rodamiento. En el caso de la
vibración RMS, el modelo LSTM presentó el mejor desempeño relativo (RMSE =
0.8275 mm/s), evidenciando una mejor capacidad para modelar esta variable en
comparación con los modelos basados en árboles.
En términos
generales, los resultados evidencian que el modelo LSTM multisalida presenta un
desempeño competitivo frente a modelos tradicionales, aunque no logra superar
consistentemente a Random Forest en las variables térmicas. Este comportamiento
sugiere que, en escenarios con baja variabilidad y alta correlación entre variables,
los modelos basados en árboles pueden capturar de manera más eficiente las
relaciones estáticas del sistema. No obstante, el modelo LSTM mantiene la
ventaja de modelar dependencias temporales, lo cual resulta relevante para
aplicaciones donde la dinámica del sistema es un factor crítico.
6.
Análisis de resultados y validación experimental
6.1
Importancia de variables en la predicción de la temperatura del estator
Con
el objetivo de identificar las variables que influyen significativamente en la
predicción de la temperatura del estator, se aplicó un análisis de importancia
por permutación sobre el conjunto de prueba. Este método evalúa la contribución
individual de cada variable midiendo el incremento del error cuando su
información es aleatorizada, manteniendo constantes las demás variables. El
desempeño base del modelo alcanzó un RMSE de aproximadamente 6.86 °C y un MAE
de 5.69 °C, valores que se tomaron como referencia. Los resultados del análisis
se presentan en la Tabla 14.
Tabla 14
Importancia por permutación de las variables en la predicción de
la temperatura del estator
|
Variable
|
Importancia media
|
Desv. estándar
|
|
Potencia activa
|
0.000052
|
0.000058
|
|
Carga del motor
|
0.000033
|
0.000054
|
|
Velocidad de rotación
|
0.000026
|
0.000068
|
|
Flujo de aire
|
0.000023
|
0.000057
|
|
Corriente
|
0.000013
|
0.000054
|
|
Voltaje
|
-0.000010
|
0.000071
|
|
Humedad
|
-0.000022
|
0.000088
|
|
Temperatura ambiente
|
-0.000035
|
0.000077
|
El incremento medio del error respecto al modelo base; valores
positivos indican mayor contribución.
Se
observa que la carga del motor y la potencia activa constituyen las variables
con mayor contribución en la predicción, evidenciando su papel dominante en la
dinámica térmica del sistema. En contraste, variables como el voltaje, la
corriente y las condiciones ambientales presentan una influencia limitada o
redundante.
6.2
Influencia de la señal de vibración en la precisión del modelo
Para
evaluar el impacto de la señal de vibración en el desempeño del modelo, se
compararon dos configuraciones: una sin incluir la variable de vibración y otra
incorporándola dentro del conjunto de entrada. Los resultados obtenidos se
presentan en la Tabla 15. Se observa que la inclusión de la vibración reduce
ligeramente el RMSE de 6.9669 a 6.8520 y el MAE de 5.7110 a 5.6844.
Tabla 15
Comparación con y sin vibración
|
Configuración
|
RMSE
|
MAE
|
|
Sin vibración
|
6.9669
|
5.7110
|
|
Con vibración
|
6.8520
|
5.6844
|
No
obstante, la magnitud de esta mejora es reducida, lo que sugiere que la
vibración no constituye una variable dominante en la predicción de la
temperatura del estator bajo las condiciones analizadas. Este comportamiento es
consistente con el análisis de correlación previamente presentado.
6.3
Prueba de Hipótesis
H₁:
Una arquitectura LSTM multivariada que incorpore todas las variables
registradas reduce el RMSE de la predicción de la temperatura del estator en al
menos un 25 % respecto a un modelo base. Para su evaluación, se comparó el
desempeño del modelo LSTM multivariado frente a un modelo base, utilizando como
métricas el RMSE y el MAE, además de estimar intervalos de confianza mediante
bootstrap. Los resultados se presentan en la Tabla 16.
Tabla 16
Resultados de la prueba de hipótesis H₁: comparación entre modelo
base y LSTM multivariado
|
Modelo
|
RMSE (°C)
|
MAE (°C)
|
|
Modelo base univariante (ARIMA/Naive)
|
6.8262
|
5.6777
|
|
LSTM multivariado (con vibración)
|
6.8791
|
5.6737
|
|
Reducción relativa RMSE (%)
|
−0.7759
|
—
|
|
IC95% reducción RMSE – límite inferior (%)
|
−2.2215
|
—
|
|
IC95% reducción RMSE – límite superior (%)
|
0.6429
|
—
|
El
modelo base alcanzó un RMSE de 6.8262 °C, mientras que el modelo LSTM obtuvo un
RMSE de 6.8791 °C, lo que corresponde a una reducción relativa de −0.7759 %. El
intervalo de confianza al 95 % incluye el valor cero, lo que indica que la
diferencia no es estadísticamente significativa. En consecuencia, la hipótesis
planteada es rechazada, ya que el modelo LSTM
multivariado no logra una mejora sustancial respecto al modelo base bajo las
condiciones analizadas.
DISCUSIÓN
Los
resultados que obtuvimos en este estudio nos dan una visión bastante completa
del desempeño del modelo LSTM multisalida cuando se trata de predecir variables
críticas en motores de inducción trifásicos. Hemos podido evaluar no solo qué
tan bien funciona el modelo, sino también dónde muestra sus limitaciones al
compararlo con otros enfoques.
Si
miramos el panorama general, el modelo LSTM tuvo un rendimiento que podríamos
calificar como competitivo. Los valores de error se mantuvieron bastante
consistentes tanto en el conjunto de prueba como en la validación temporal
cruzada, lo cual es una buena señal de que el modelo tiene capacidad para
generalizar. Esto va en línea con lo que se ha venido reportando en la
literatura científica, donde las arquitecturas recurrentes han probado ser
bastante efectivas para capturar dependencias temporales en sistemas
industriales que son, por naturaleza, complejos (Deng et al., 2021; H. Wang et al.,
2023). Ahora bien, hay algo
interesante que notamos: el modelo no logra superar de manera consistente a
algoritmos como Random Forest, particularmente cuando hablamos de predecir
variables térmicas.
Esta
observación resulta llamativa porque coincide con lo que otros estudios
recientes han encontrado. Qiu et al. (2023) y Tama et al. (2023) han señalado que modelos como Random Forest
pueden funcionar mejor en situaciones donde las variables están muy
correlacionadas y no presentan mucha variabilidad. La razón tiene que ver con
cómo estos algoritmos capturan relaciones no lineales de forma bastante
eficiente, sin necesidad de modelar explícitamente la estructura temporal como
lo hacen las LSTM. Lo que esto nos dice es que la ventaja teórica que tienen
las redes LSTM para modelar el tiempo no siempre se traduce en una reducción
significativa del error, sobre todo cuando trabajamos con datos que vienen de
entornos controlados.
Uno
de los descubrimientos más interesantes fue la tendencia del modelo LSTM a
producir predicciones que están, digamos, suavizadas. Esto se nota claramente
cuando comparamos los valores reales con los que predice el modelo. No es algo
nuevo, en realidad; ya se había reportado antes. Zhang et al. (2020) mencionan que las redes recurrentes suelen
enfocarse más en seguir la tendencia general de la señal y, como consecuencia,
pierden capacidad para capturar esas fluctuaciones rápidas de alta frecuencia.
En nuestro caso, creemos que esta limitación tiene dos causas: por un lado, la
arquitectura misma del modelo, y por otro, la naturaleza del dataset que
usamos, que tiene una variabilidad más bien limitada.
El
análisis de importancia por permutación nos permitió identificar algo que,
pensándolo bien, tiene mucho sentido desde el punto de vista físico. Las
variables eléctricas y operativas, especialmente la potencia activa y la carga
del motor, son las que más influyen en la predicción de la temperatura del
estator. Esto es coherente con lo que sabemos sobre cómo funcionan los motores
eléctricos: el calor se genera principalmente por las pérdidas eléctricas y
está directamente relacionado con el nivel de carga al que opera el motor (Lei et al., 2020). En contraste, las variables ambientales
tuvieron una contribución bastante marginal, lo que nos hace pensar que quizás
hay cierta redundancia en el dataset o simplemente no variaban lo suficiente.
Cuando
analizamos la variable de vibración, nos encontramos con que su inclusión
mejora un poco el desempeño del modelo, aunque el impacto no es tan grande como
esperábamos. Una posible explicación es que esta variable tiene una correlación
menor con las variables térmicas. Neupane & Seok (2020) han comentado algo similar, destacando que
las señales de vibración pueden necesitar enfoques específicos para su modelado
porque son altamente no lineales y muy sensibles a factores externos.
La
prueba de hipótesis que planteamos nos ayudó a evaluar de forma rigurosa qué
tanto aportaba realmente el modelo LSTM multivariado comparado con un modelo
más simple. Los resultados fueron, en cierto modo, sorprendentes: la reducción
del error no resultó ser estadísticamente significativa, lo que nos llevó a
rechazar la hipótesis inicial. Este hallazgo es importante porque nos recuerda
que un modelo más complejo no necesariamente va a funcionar mejor. Realmente
refuerza la idea de que debemos elegir arquitecturas que se ajusten bien a las
características de nuestros datos.
Cuando
examinamos los residuos desde un punto de vista estadístico, encontramos que el
modelo no muestra sesgos sistemáticos importantes, lo cual es positivo. Sin
embargo, las distribuciones de error en las variables térmicas no siguen de
manera estricta una distribución normal. Esto no es del todo inesperado si
consideramos la naturaleza no lineal de los sistemas electromecánicos y el
ruido que inevitablemente está presente en cualquier proceso de medición (Allal & Khechekhouche, 2022). Aun así, los intervalos de confianza que
calculamos usando bootstrap muestran poca variabilidad en las métricas, lo que
nos da confianza en que el modelo es estable.
Si
juntamos todas estas piezas, lo que vemos es que los modelos de aprendizaje
profundo como las LSTM son herramientas muy potentes para analizar series
temporales, eso está claro. Pero su desempeño real depende mucho de la calidad
de los datos con los que trabajamos, de cuánta variabilidad tienen y de qué tan
complejos son. En escenarios donde las condiciones están bastante controladas y
las dinámicas son relativamente estables, los modelos más tradicionales pueden
dar resultados que son comparables o incluso mejores.
Para
cerrar, creemos que estos hallazgos abren puertas interesantes para futuras
investigaciones. Una dirección prometedora sería desarrollar modelos híbridos
que combinen la capacidad de las redes LSTM para modelar el tiempo con enfoques
probabilísticos o basados en árboles de decisión. También vale la pena
considerar la incorporación de variables adicionales que nos ayuden a capturar
mejor esas fluctuaciones transitorias que el sistema presenta. Además, sería
útil explorar arquitecturas más avanzadas, como los modelos basados en
mecanismos de atención o redes neuronales que integren componentes físicos de
manera explícita. Todo esto con el objetivo de mejorar no solo la precisión de
las predicciones, sino también su interpretabilidad cuando las aplicamos en
contextos industriales reales.
CONCLUSIONES
En este
estudio se desarrolló un modelo LSTM multisalida con el objetivo de predecir,
de forma conjunta, variables térmicas y vibracionales en motores de inducción
trifásicos. A partir de los datos experimentales utilizados, se pudo comprobar
que el modelo reproduce de manera adecuada el comportamiento general del
sistema, manteniendo resultados estables tanto en el conjunto de prueba como en
los esquemas de validación aplicados.
En relación
con el desempeño, los valores obtenidos (RMSE entre 6.8 y 7.0 °C en temperatura
y alrededor de 0.83 mm/s en vibración) muestran que el modelo funciona de
manera consistente. Sin embargo, al comparar estos resultados con los obtenidos
mediante Random Forest, se observa que este último logra un ajuste ligeramente
mejor en variables térmicas. Esto sugiere —y es importante destacarlo— que
aumentar la complejidad del modelo no siempre se traduce en una mejora directa
en la precisión.
Al analizar
las predicciones (especialmente en las figuras de resultados), se nota un
aspecto interesante: el modelo tiende a suavizar la señal. Es decir, sigue bien
la tendencia general, pero pierde detalle en cambios rápidos. Esto no es un
error como tal, sino más bien una característica del enfoque LSTM y también del
tipo de datos utilizados. En consecuencia, el modelo resulta útil para
monitoreo general, aunque no es el más adecuado cuando se requiere capturar
eventos transitorios.
Otro punto
relevante tiene que ver con las variables. En este caso, la potencia activa y
la carga del motor aparecen como los factores más influyentes en la predicción
de temperatura, lo cual coincide con el comportamiento físico esperado del
sistema. Por el contrario, las variables ambientales aportan menos información,
y la vibración, aunque útil, tiene un impacto más bien complementario.
Respecto a la
hipótesis planteada, los resultados muestran que el modelo LSTM no logra una
mejora significativa frente a un modelo base. Este resultado puede parecer
contraintuitivo al inicio, pero en realidad refuerza una idea clave: no siempre
el modelo más complejo es el más adecuado, especialmente cuando los datos no
presentan suficiente variabilidad.
Finalmente, el
análisis de residuos y los intervalos de confianza obtenidos mediante bootstrap
permiten afirmar que el modelo es estable, aunque las distribuciones no son
completamente normales, algo esperable considerando la naturaleza no lineal del
sistema.
A partir de
estos resultados, se abren varias líneas de trabajo interesantes. Por ejemplo,
combinar modelos (híbridos) podría aprovechar lo mejor de cada enfoque. También
sería útil incorporar nuevas variables o explorar arquitecturas más avanzadas
que permitan capturar mejor los cambios rápidos en el sistema.
CONTRIBUCIÓN DE LOS AUTORES
Geovanna
Shirley Agila Aguinda se encargó de: definición del problema de investigación y
concepción del estudio; diseño de la metodología y estructuración del enfoque
experimental; implementación del pipeline de análisis y procesamiento del
conjunto de datos; análisis e interpretación de los resultados obtenidos; y redacción
del manuscrito.
Corrales
Bonilla Johnatan Israel se encargó de: orientación científica y metodológica
durante el desarrollo del estudio; supervisión del diseño experimental y
validación de la metodología aplicada; revisión de la implementación de las
técnicas de aprendizaje profundo; validación de los resultados obtenidos; y revisión
crítica del manuscrito, aportando observaciones para mejorar la coherencia, el
rigor metodológico y la calidad académica.
REFERENCIAS BIBLIOGRÁFICAS
Allal, A., & Khechekhouche, A. (2022). Diagnosis
of Induction Motor Faults Using the Motor Current Normalized Residual Harmonic
Analysis Method. International Journal of Electrical Power & Energy
Systems, 141, 108219. https://doi.org/10.1016/j.ijepes.2022.108219
Cen, J., Yang, Z.,
Liu, X., Xiong, J., & Chen, H. (2022). A Review of Data-Driven Machinery
Fault Diagnosis Using Machine Learning Algorithms. Journal of Vibration
Engineering & Technologies, 10, 2481-2507.
https://doi.org/10.1007/s42417-022-00498-9
Deng, F., Bi, Y.,
Liu, Y., & Yang, S. (2021). Deep-Learning-Based Remaining Useful Life
Prediction Based on a Multi-Scale Dilated Convolution Network. Mathematics,
9(23), 3035. https://doi.org/10.3390/math9233035
Gangsar, P., &
Tiwari, R. (2020). Signal Based Condition Monitoring Techniques for Fault
Detection and Diagnosis of Induction Motors: A State-of-the-Art Review. Mechanical
Systems and Signal Processing, 144, 106908.
https://doi.org/10.1016/j.ymssp.2020.106908
Hughes, R.,
Haidinger, T., Pei, X., & Vagg, C. (2023). Real-Time Temperature Prediction
of Electric Machines Using Machine Learning with Physically Informed Features. Energy
and AI, 14, 100288. https://doi.org/10.1016/j.egyai.2023.100288
Jiao, J., Zhao,
M., Lin, J., & Liang, K. (2020). A Comprehensive Review on Convolutional
Neural Network in Machine Fault Diagnosis. Neurocomputing, 417,
36-63. https://doi.org/10.1016/j.neucom.2020.07.088
Kirchgässner, W.,
Wallscheid, O., & Böcker, J. (2021). Estimating Electric Motor Temperatures
With Deep Residual Machine Learning. IEEE Transactions on Power Electronics,
36(7), 7480-7488. https://doi.org/10.1109/TPEL.2020.3045596
Lei, Y., Yang, B.,
Jiang, X., Jia, F., Li, N., & Nandi, A. K. (2020). Applications of Machine
Learning to Machine Fault Diagnosis: A Review and Roadmap. Mechanical
Systems and Signal Processing, 138, 106587.
https://doi.org/10.1016/j.ymssp.2019.106587
Neupane, D., &
Seok, J. (2020). Bearing Fault Detection and Diagnosis Using Case Western
Reserve University Dataset with Deep Learning Approaches: A Review. IEEE
Access, 8, 93155-93178. https://doi.org/10.1109/ACCESS.2020.2990528
Nikfar, M.,
Bitencourt, J., & Mykoniatis, K. (2022). A Two-Phase Machine Learning
Approach for Predictive Maintenance of Low Voltage Industrial Motors. Procedia
Computer Science, 200, 111-120.
https://doi.org/10.1016/j.procs.2022.01.210
Qiu, S., Cui, X.,
Ping, Z., Shan, N., Li, Z., Bao, X., & Xu, X. (2023). Deep Learning
Techniques in Intelligent Fault Diagnosis and Prognosis for Industrial Systems:
A Review. Sensors, 23(3), 1305. https://doi.org/10.3390/s23031305
Singh, V.,
Gangsar, P., Porwal, R., & Atulkar, A. (2023). Artificial Intelligence
Application in Fault Diagnostics of Rotating Industrial Machines: A
State-of-the-Art Review. Journal of Intelligent Manufacturing, 34(3),
931-960. https://doi.org/10.1007/s10845-021-01861-5
Tama, B. A.,
Vania, M., Lee, S., & Lim, S. (2023). Recent Advances in the Application of
Deep Learning for Fault Diagnosis of Rotating Machinery Using Vibration
Signals. Artificial
Intelligence Review, 56,
4667-4709. https://doi.org/10.1007/s10462-022-10293-3
Theissler, A.,
Pérez-Velázquez, J., Kettelgerdes, M., & Elger, G. (2021). Predictive Maintenance Enabled by Machine
Learning: Use Cases and Challenges in the Automotive Industry. Reliability
Engineering & System Safety, 215, 107864.
https://doi.org/10.1016/j.ress.2021.107864
Wang, H., Zheng,
J., & Xiang, J. (2023). Online Bearing Fault Diagnosis Using Numerical
Simulation Models and Machine Learning Classifications. Reliability
Engineering & System Safety, 234, 109142.
https://doi.org/10.1016/j.ress.2023.109142
Wang, L., Qiu, F.,
& Li, Z. (2024). Short and Long Term Memory Method for Predicting the
Temperature of Motor Stator Based on Harris Eagle Algorithm Optimization. Case
Studies in Thermal Engineering, 59, 104454.
https://doi.org/10.1016/j.csite.2024.104454
Xu, Z., &
Saleh, J. H. (2021). Machine
Learning for Reliability Engineering and Safety Applications: Review of Current
Status and Future Opportunities. Reliability Engineering & System Safety,
211, 107530. https://doi.org/10.1016/j.ress.2021.107530
Zhang, S., Zhang,
S., Wang, B., & Habetler, T. G. (2020). Deep Learning Algorithms for
Bearing Fault Diagnostics—A Comprehensive Review. IEEE Access, 8,
29857-29881. https://doi.org/10.1109/ACCESS.2020.2972859
Zhao, Z., Li, T.,
Wu, J., Sun, C., Wang, S., Yan, R., & Chen, X. (2020). Deep Learning
Algorithms for Rotating Machinery Intelligent Diagnosis: An Open Source
Benchmark Study. ISA Transactions, 107, 224-255.
https://doi.org/10.1016/j.isatra.2020.08.010
Zhu, Z., Lei, Y.,
Qi, G., Chai, Y., Mazur, N., An, Y., & Huang, X. (2023). A Review of the
Application of Deep Learning in Intelligent Fault Diagnosis of Rotating
Machinery. Measurement, 206, 112346.
https://doi.org/10.1016/j.measurement.2022.112346